ARTICLES
Citus Data - How it enables distributed postgres
- 6 minutes read - 1205 wordsCitus: Distributed PostgreSQL for Data-Intensive Applications paper can be downloaded here.
Recently, our team got a request to provide a solution to shard Postgres. One of the solutions that we discussed was Citus. I have heard about the product and seen their blogs related to Postgres in the past but never used it. I thought it would be fun to read about its internal workings.
If you find something wrong on the notes, please send a pull request. Before digging their white paper, let’s take a step back and ask what is sharding and why do we need sharding?
Certainly, I haven’t used the word “shard” in my day-to-day life. 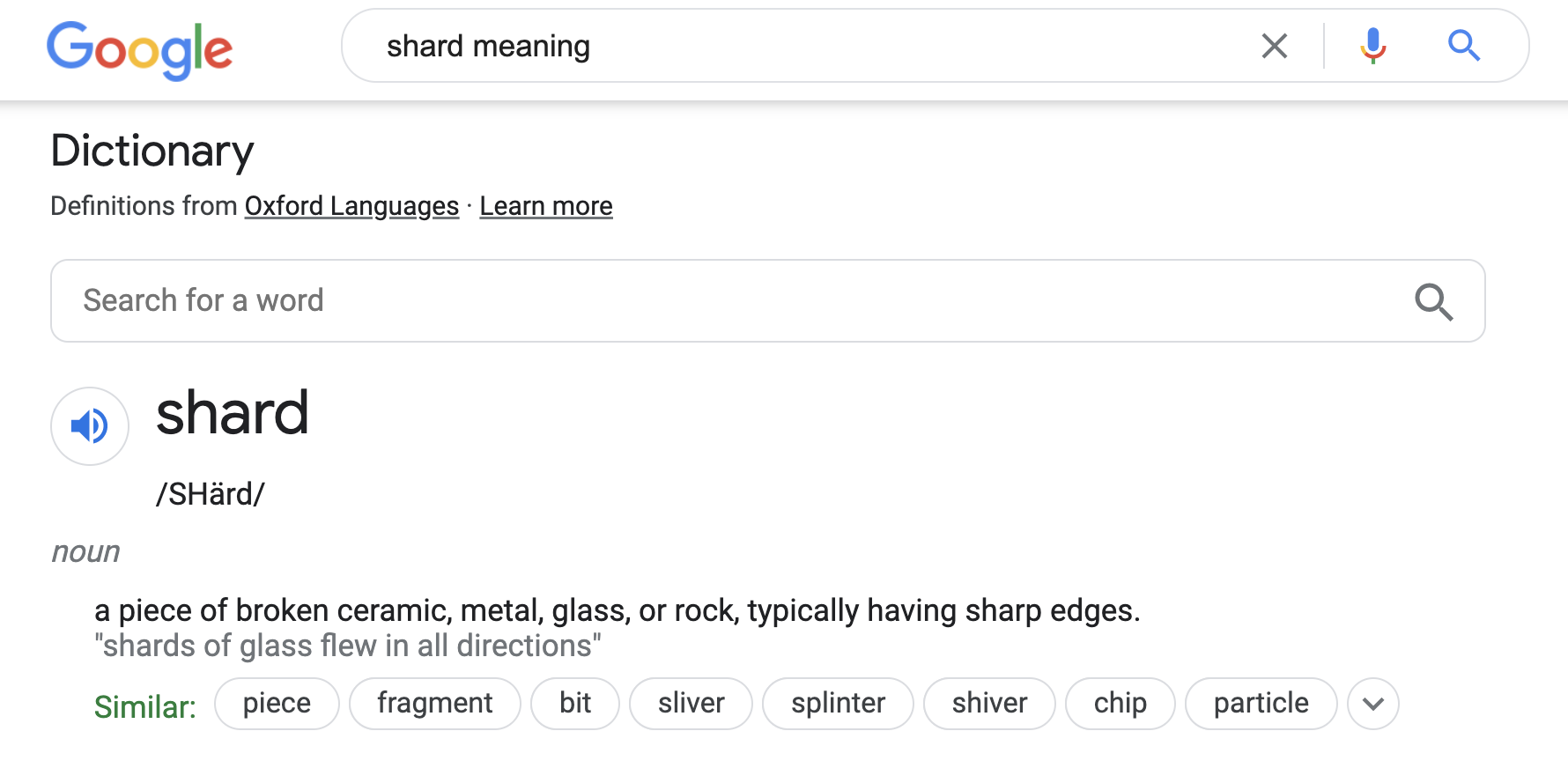 .
.
There two ways one can scale their systems:
- Vertical Scaling - Acquiring more resources (eg. CPU, Memory, Disk) on the same hardware
- Horizontal Scaling - Acquiring more resources by adding additional hardware
Sharding comes from the concept of Horizontal Scaling. Say, the maximum disk space of servers that you have is 11 TB. What if we want to store more than that in a single table/database? Traditional approach is vertical scaling i.e) trying to add more disks on the server, but at some point it will hit the ceiling. Nothing one can do other than growing horizontally. A good introduction about database sharding from Digital Ocean.
What is Citus?
- It is a PostgreSQL extension to store data, query (which includes transactions) acorss a cluster of PostgreSQL servers
- Open sourced [1]
Postgres core itself doesn’t come with features for horizontal scaling. Postgres’ wiki on sharding and Gitlab’s experiment using FDW are good resources.
Alternate approaches are:
- Build the database engine from scratch and write a layer to provide over-the-wire SQL compatibility - YugaByte, Cockroachdb etc.
- Fork an open source database systems and build new features on top of it - Orioledb, Neondatabase
- Provide new features through a layer that sits between the application and database, as middleware - ShardingSphere
 .
.
I couldn’t find a lot of options for horizontal scaling Postgres. Looks like many agrees. MySQL has Vitess
The types of applications that requires distributed postgres is broadly divided into four categories:
- Multi-tenant/SaaS
- An application which stores data of multiple tenants in the same database.
- Data is relatively specific to the tenant
- Traditional approach (application level sharding) is spinning up individual database/server for each tenant and then mapping that information on the application itself. There is an operation overhead when moving data around, performing schema changes and analytics across tenants.
- The alternative approach is the database level sharding. Application doesn’t need to track which tenant is stored in which server. Use a shared schema with tenant ID columns. The dbms should be capable of routing arbitrarily complex SQL queries of a specific tenant to a specific server. Should provide support for flexible data type (achieved using JSONB) and control over tenant placements to avoid noisy-neighbor problems
An example of a messaging system which stores multiple tenant data. AKA slack. 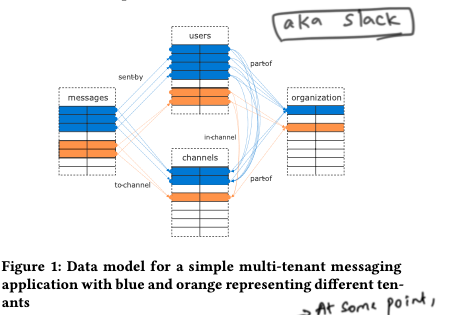 .
.
Real-time analytics
- Used for system monitoring, ingesting IoT data, user browsing/behavioral data etc.
- System should be capable of supporting parallel bulk loading, INSERT..SELECT to create rollup tables.
High-Performance CRUD
- CRUD stands for Create, Read, Update and Delete
- An example of such system will be an e-commerce website
- Generally, they are highly concurrent, expects low latency and needs to do joins
Data Warehousing
- Combines data from different sources into a single database system to generate ad-hoc reports
- Generally don’t have low latency, high concurrency requirements
How citus provides solutions for the above use cases is the rest of the paper.
Architecture
All servers in a Citus cluster, run PostgreSQL with Citus extension. It has two components – Coordinator and Worker. Typically set up will have 1 Coordinator and 0 or more workers. Coordinator can also be scaled if throughput becomes the bottleneck. If there is no worker then the Coordinator will take that role.
It uses extensions api to change the behavior. It replicates custom types and functions across all servers.
PostgreSQL extension APIs This is perhaps one of the best features of Postgres. One can change the behavior of PostgreSQL by defining hooks (custom logic). AFAIK, Oracle, MySQL does not have extensions. Citus uses the following hooks
User-defined functions Callable from SQL inside a transaction usually to manipulate Citus metadata
Planner and executor hooks Citus checks whether the query involves a Citus table, if so intercepts it and creates a plan that contains a CustomScan node a. CustomScan is an execution node in the query plan. It calls the Citus distributed query executor which returns results then that will be returned to Postgres query executor.
Transaction callbacks, utility hook and background workers are other hooks used by Citus.
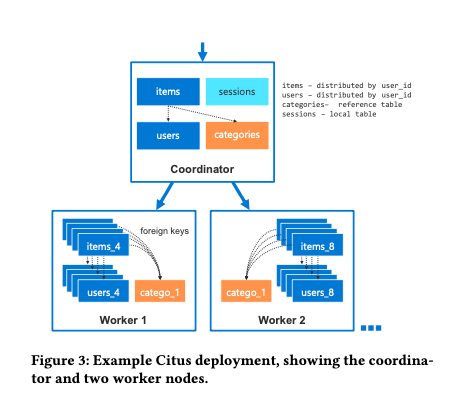
Citus has two types of tables:
1. Distributed table They are hash-partitioned along a distribution column into multiple logical shards with each shard containing a contiguous range of hash values. From the above diagram, items and users table are distributed tables with distributed column of user_id. One worker node can contain multiple logical shards, so that they can be rebalanced.
2. Reference table These are replicated to all nodes including coordinator. Joins between distributed tables and reference tables used the local replica of the reference table. From above, Categories is a reference table.
I see a semblance of Star schema (fact and dimension tables).
Co-location:
Citus can make sure that the same range hash values are always on the same worker node among distributed tables. From above, users_4, items_4 (both have hash value of 4) will reside on the same worker node [2]. Main benefit is joins and foreign keys are implemented within a worker node.
Data rebalancing:
AKA shard rebalancing. By default, the rebalancer moves shards until it reaches an even number of shards across worker nodes. Also, one can rebalance based on data size or using custom definitions by cost, capacity and constraint function. They do that using PostgreSQL logical replication [3].
Distributed Query planner and executor:
Fast path planner handles queries on a single table with a single distribution column value. Router planner handles complex queries that can be scoped to one set of co-located shards. Logical planner handles queries across shards by constructing a multi-relational algebra tree.
Executor runs in parallel by opening multiple connections per shard instead of using PostgreSQL parallel query capability. They found that it is more versatile and performant however with the downside of opening multiple connections. PostgreSQL connections are expensive. They avoid using “slow start” - technique to open a new connection for ever 10ms. Also, paper specified that Crunchy is working on improving the connection handling with the upstream - a welcoming news.
Distributed transactions are implemented using Two-Phase commit protocol. Citus uses pg_auto_failover extension for implementing HA.
The last part of the paper is about benchmarks. It seems like Citus is winning in most of the scenarios. I generally take benchmarks with a pinch of salt.
Open Questions:
- What’s the difference (in features) between open source Citus and paid?
- Nothing. While I was reading the paper, Citus completely open sourced all their enterprise features. Impressed with their work.
- Nothing. While I was reading the paper, Citus completely open sourced all their enterprise features. Impressed with their work.
- Does each tenant have its own shard (aka table) in a worker node?
- How does it manages things like DDL change, sequences, truncate?